RHQ 4.10
Alternate Agent Models
I'm going to extend the use of this page to talk about the different management scenarios that we'll need to account for.
Grid
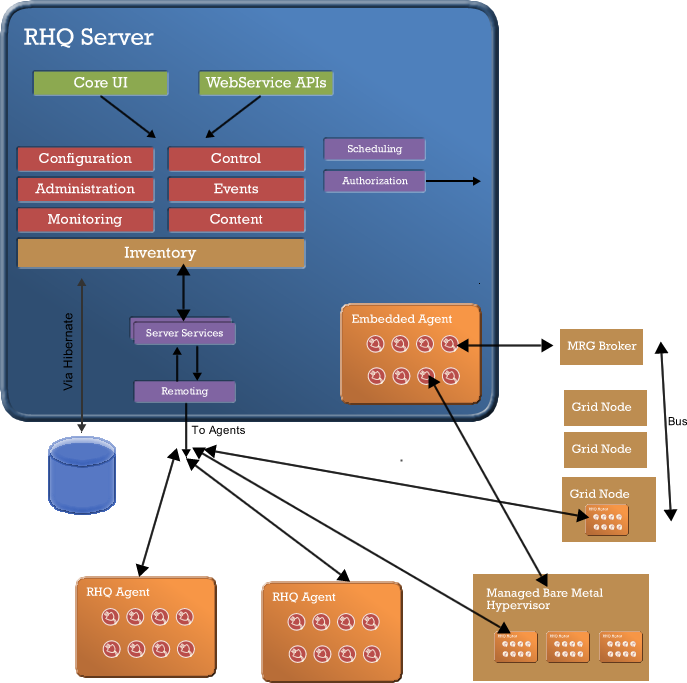
Grid is looking for two separate scenarios. The first kind of MRG grid would look for us to support the monitoring features of the MRG infrastructure. This is possible, initially, by building a fairly straightforward adapter plugin that would run centrally and communicate via the MRG bus. It should be able to use MRG management infrastructure to auto-discover and inventory the necessary parts of the system as they are already deployed and support listening for and tracking monitoring data. With the possible addition of some transformations of MRG schema data to our metadata model we should be able to add extended MRG information to our inventory and monitoring model without large changes to our infrastructure.
The second scenario would be where we look to utilize platform management on the GRID nodes. This would require us to deploy our existing agent infrastructure fully in parallel with the GRID, but would give the GRID nodes all of our capability to run any of our supported plugins. The next step in this scenario would be to support tunneling the communications model of our agent-server infrastructure over the bus in order to support the single link situations like InfiniBand only setups. The impact of these setups is the deployment of the agent infrastructure (the jvm and the agent).
An alternate model to the second scenario is to try to build the management functionality in the MRG model as well as the platform model. This would require full on support for all the platform subsystems and would take significantly more time to develop and result in parallel agent and plugin infrastructures. We could build a MRG end-point for the server that mirrors the functionality of our existing agent-server endpoint, but to support all of the plugin subsystems in the MRG client would also take significant time. With all of the complex capabilities of the platform, defining full formats and behaviors for the complete specification would involve a lot of composite objects and synchronization models.
Virtualization
A few scenario variations exist for managing virtualization.
Standard virtualization will probably involve us running the agent on the dom0 and domU's to get full platform capabilities at all levels. We'll be able to manage anything for a virtual OS that we can manage for a standard OS. The dom0 will give us create and provisioning of guests. The combined inventory model will show the guests under the dom0.
Bare Metal Standalone Hypervisor scenarios present a different problem of not being able to support our agent infrastructure. In these cases, we should default back to our alternate-agent support model of using a central pool of embedded agent's to act as the remote agent connector. In this case, we'd look to use the exposed remote management interfaces of the technology we're connecting to. (e.g. through xen-api) In this scenario, we could either look to be provisioned onto guest OS'es to allow for full platform management capabilities or keep at arms length and only use the remote management technologies for virt level management and monitoring.
Full Platform
The full platform scenario supports our complete extension model where plugin developers will have the full agent infrastructure to depend on and can quickly get features up and running. There are facets to each of our subsystems that reach right down between the agent and server model that don't necessarily translate to alternative agent models. For example, we allow the user to coordinate the collection schedules for metrics from a central system that allows templates and group oriented customizations to collection configuration. This assumes a certain model that provides richness, but that not everything embraces. For the things that can't embrace it, see the next section, but where we can use it, it obviates the plugin (agent, daemon) developer from having to rebuild what hundreds of others already have.
Remote only
The management world is somewhat divided into the systems-only or systems-and-applications categories. Or alternatively the agentless/builtin agent vs. the custom agent. This isn't going to change anytime soon and the platform has to be built to expect to integrate with technologies at the different levels while not ending up being just an erector set that is as impossible to setup and install as some of our competitors. The remote agent model is one where we utilize our capability for maintain server-embedded agents with infrastructure that can run custom developed plugins written more for remote management. It's essentially using our standard plugin api's to support agentless setups. These setups are not going to be able to support our richer application and content functionality, but as they exist already it makes complete sense to fully support these. It is essentially our mechanism to support alternative agent protocols. Through this model we can support platforms that can't run our agent (bare metal hypervisors, network infrastructure) through their existing built-in agents. Using SNMP from our embedded server agent to talk SNMP to the network switches supports that platform.
Open Agent to Server communications protocol
This page is to discuss the idea of supporting other agents then the core agent through the creation of an open protocol spec for agent to server communication. The idea being that those who wish not to use our agent would be free to write their own. Whilst I'd like to avoid both the proliferation of agents and the duplication of development functionality, it may be possible to start this process to allow a subset of functionality to be done through a limited open api. The entire API covers every subsystem and has significant integration effort in both behavior and data transfer. The inventory synchronization model is complex and would be hard to duplicate to many agents with good reason. But a simpler interface that only allows interaction with the content subsystem is a real possibility. We would still need to figure out how to deal with reliable delivery, queue request synchronization and the built-in bi-directional content streaming, but this should be possible if we limit the scope of the solution.
I still think it is a dangerous idea if each developer to the platform looks at this as a reason to write their own daemon. When looking at the individual case, perhaps that isn't such a bad decision. When taken with the context of the many products in use by customers and the complex deployment needs the agent delivers a lot of necessary functionality. In the end, there would likely be a lot of duplication of that functionality. This doesn't mean its never the right idea just that we have to keep the whole picture in mind when making these sorts of decisions.